オンラインPDF圧縮
オンラインPDF圧縮 オンラインPDF圧縮
オンラインPDF圧縮
PDF形式とは色んなOSの間にファイルを共有する時、書式などを崩さないようにAdobe会社から開発されるファイル形式の一種です。数多くのメリットがありながら編集し難いというデメリットもあります。ではPDF形式のファイルを編集するのは絶対無理のでしょうか?今日はこの記事で皆さんのこの疑問についてしっかり解明させて下さい。
一、直接にPDFファイルから特定範囲内でテキスト抽出する方法
二、PDFファイルをtext、txt(テキスト)形式に変換して全テキスト抽出する方法
三、スキャン版PDFファイルからOCR(文字認識)機能でテキストを抽出する方法
一、直接にPDFファイルから特定範囲内でテキスト抽出する方法
直接にPDF形式のファイルからテキストをコピーして、他の形式のファイルへ貼り付けたいならばまず「Adobe Acrobat」というAdobe会社から開発されたPDFファイル処理専門ソフトの力に借ります。まずは公式サイトから「Adobe Acrobat」のインストールパッケージをダウンロードして、予めパソコンへインストールしておいてください。これからは「Adobe Acrobat」でPDF形式のファイルからテキストを抽出する方法を案内します。
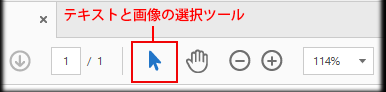
1.処理したいPDFファイルを予め開いて、ソフトの「テキストと画像の選択ツール」を選択します。
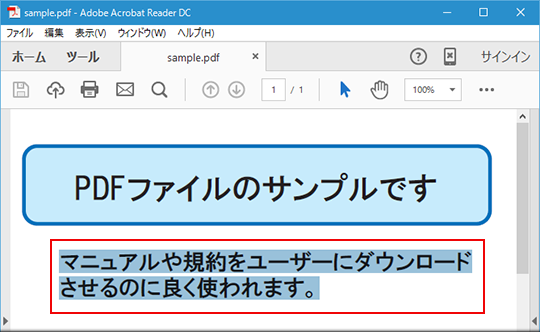
2.それから開けているPDFファイルの中抽出したいテキストを選定して、編集>コピーの順でボタンを押して、またはホットキー(Ctrl+Cキー)でテキストをコピーシミあす。
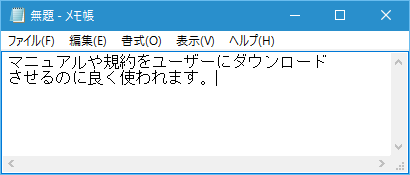
3.そしてコピーされるテキストを貼り付け先で「貼り付け」、或いはホットキー(Ctrl+Vキー)で貼り付けてばいいです。メモ帳やWordファイルに直接貼り付けます。
「Adobe Acrobat」によって、簡単にPDF形式ファイルから特定範囲のテクストを選択して、複製することができるが、テキストの書式が失われる場合もあるのでご注意を。また、直接にテキストをコピーして抽出することができないPDFファイルもあります。もしファイルを丸ごとテキストを抽出したければ、次に紹介されるソフトで試してください。
二、PDFファイルをtext、txt(テキスト)形式に変換して全テキスト抽出する方法
「easePDF」というオンラインPDFコンバーターによって、手元の編集不能PDFファイルを簡単に他の編集可能のtxt形式に変換することが出来ます。その後、変換先のファイルにテキストを編集すればいいです。
1.easePDFのホームページを開いたら、txtに変換する為例示のスクショにマークされたボタンを押してください。ご覧の通り、txt以外にも沢山の形式に対応できるので、興味があればどうぞ試してください。
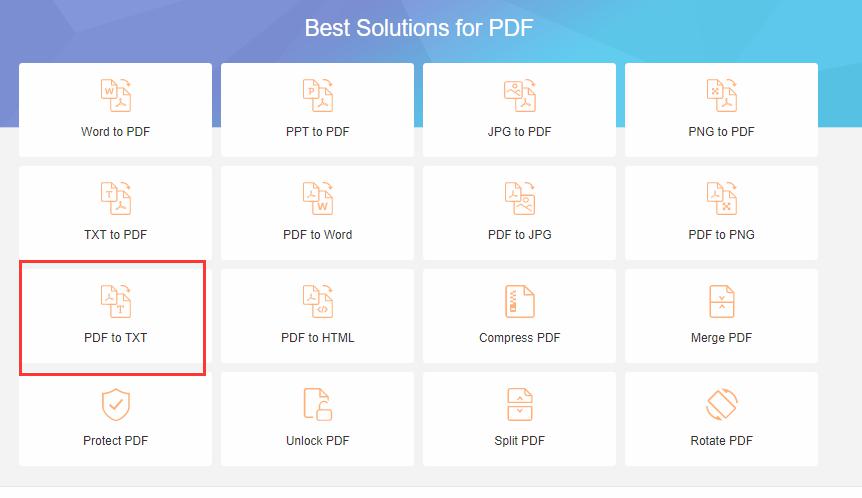
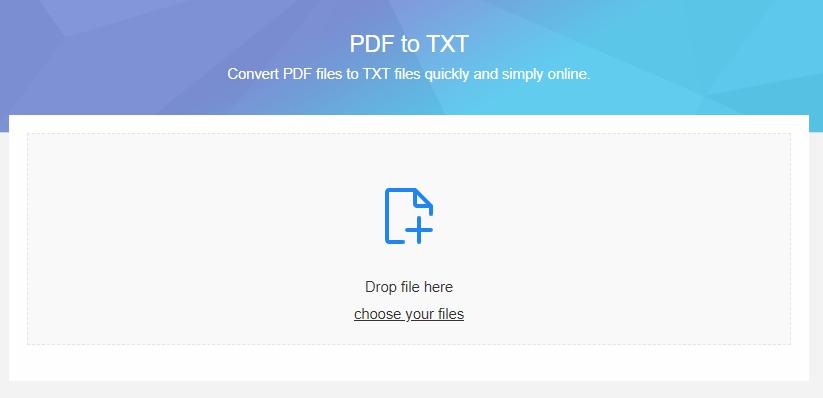
2.そしてはテキストを抽出したいPDFファイルを選んで、サイトにアップロードする必要があります。次の画面に真ん中のファイル追加エリアへ直接にPDFファイルをドロップするか、又はプラスボタンをクリックしてから参照ウインドウでファイルを見つけて選ぶのか、どっちでも簡単にファイルを追加できます。
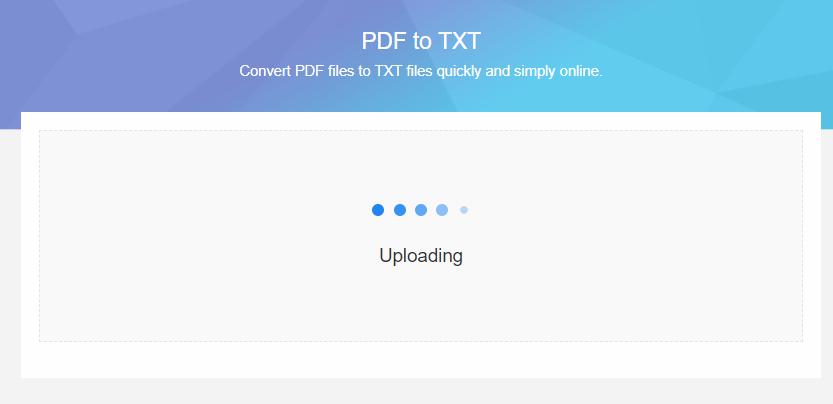
3.PDFからtxtへの変換は全自動的なので、コンバート完了まで待ってればいいです。その間にはブラウザを開いてまま保ってください。最後に変換完了後のtxtファイルをパソコンにダウンロードするのを忘れないでください。
三、スキャン版PDFファイルからOCR(文字認識)機能でテキストを抽出する方法
紙製品からスキャンしてデジカル化されたテキストを一部のみPDFファイルから抽出したければ、OCR(文字認識)機能があるAcrobatを使わなければなりません。ここで簡単にAcrobatでスキャン版PDFファイルからテキストの抽出方法を紹介します。
注意:OCRをPDFに適用するには元のスキャナの解像度に要求があります。72dpi以下に設定されたPDFファイルに適用できない、たとえ150dpiでも精度があまり高くありません。300dpiでスキャンすると、最適なテキストが生成されます。
1.Acrobat を起動し、OCR を適用する PDF ファイルを開きます。
そしてソフトによって、操作を決めます。
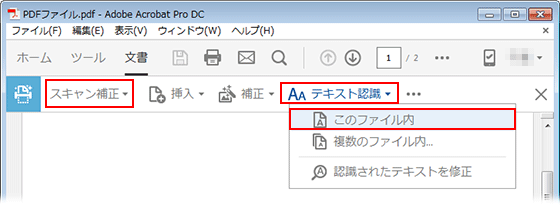
Acrobat DC:
ツール/スキャン補正/テキスト認識/このファイル内の順序で選択します。
Acrobat XI:
ツールパネルから、テキスト認識/このファイル内の順序で選択します。
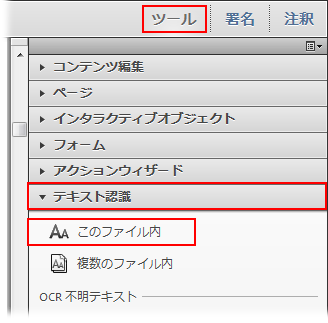
2.OCR を適用するページ範囲を選択します。
Acrobat DC:
第 2 ツールバーから選択します。
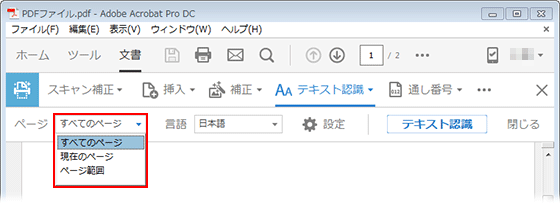
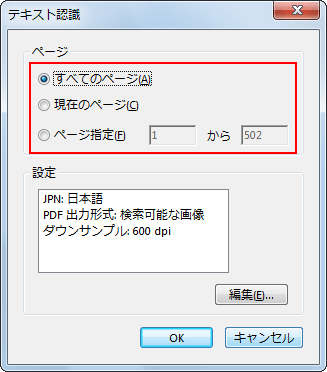
Acrobat XI:
テキスト認識ダイアログボックスから選択します。
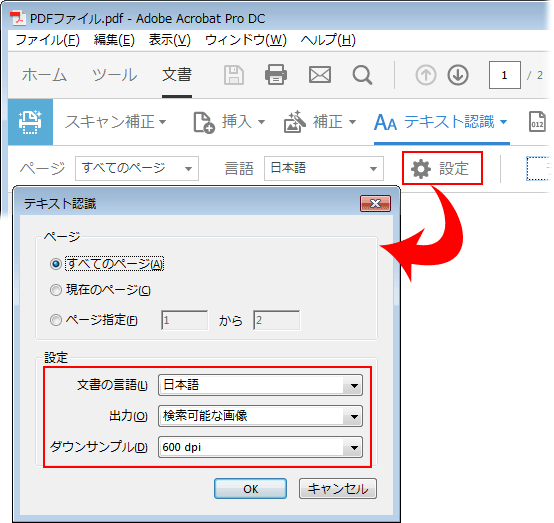
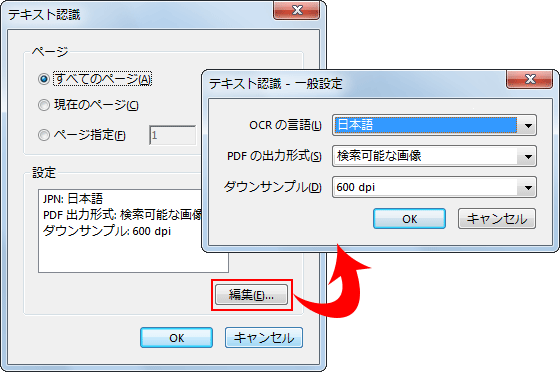
3.続いては需要によって最後の設定を行います。文書の言語、出力先設定を日本語のテキストにしてください。設定が済んだら「OK」をクリックして、OCRを適用します。
以上ではPDFファイルから特定範囲内のテキスト文字、もしくは丸ごとに全テキスト及びスキャン版文書のPDFファイルからテキストを抽出する方法のまとめて紹介でした。長文だからご自分の需要によって必要な部分だけで読むと時間を節約するのがオススメです。もしこれらの方法の中に何か分からない部分があればご遠慮なく、コメントで教えてください。